






Transformer对大模型界的影响力不言而喻,ChatGPT、Sora、Stable Difusion等知名模型皆使用了该架构。
但有一个很明显的缺点,其注意力复杂度的二次方增长在处理书籍、PDF等超长文档时会显著增加算力负担。
虽然会通过滑动窗口注意力和稀疏注意力等技术来解决这一问题,在处理极长序列时仍存在局限性。
因此,谷歌的研究人员提出了全新架构TransformerFAM,可以无缝与预训练模型集成,并通过LoRA进行少量精调从而大幅度提升模型性能。

研究人员在1B、8B和24B三种参数的Flan-PaLM大语言模型上评估了Transformer FAM的性能。实验结果显示,与Transformer架构相比,TransformerFAM在长序列任务上取得了好的能力并且资源消耗更低。
论文地址:https://arxiv.org/abs/2404.09173
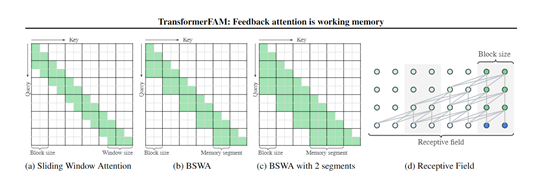
TransformerFAM的技术灵感来自人脑中工作记忆的机制。研究人员发现,大脑中的工作记忆能力是由前额叶皮层和视床之间的反馈循环维持的,即持续的神经元脉冲活动形成了一个反馈回路,从而实现了对短期记忆的维持和更新。
受此启发,研究人员设计了一个集成在Transformer中的反馈循环,使得注意力机制不仅可以关注输入序列,还能自我关注自身的潜在表示,使大模型能够存储超长和更新全局上下文信息。
简单来说,可以把TransformerFAM看成是一个”便签本”,可以帮助大模型记住很多短暂、细小的事情,又不会对内存、算力造成过多的负担。
反馈注意力记忆
反馈注意力记忆(Feedback Attention Memory,FAM)是TransformerFAM架构的核心模块,主要通过反馈循环使神经网络能够注意到自身的潜在表示,从而允许大模型处理超长的输入序列。
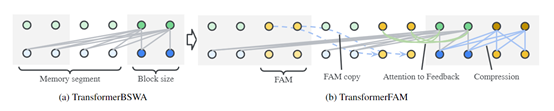
研究人员在每个Transformer层中都加入了FAM模块,在自注意力过程中被激活,使得输入查询不仅关注当前块和滑动窗口覆盖的过去记忆段,还能关注前一步的FAM状态,将全局上下文知识融入当前表示。
同时一个专门的FAM查询则负责根据当前块和上一步的FAM,更新后续的FAM状态以实现全局上下文信息的传递。
这种巧妙设计使得每个Transformer层都能够维持一个与其抽象层次相对应的分布式工作记忆状态。
块内压缩
块内压缩是Transformer架构中处理长序列数据的关键技术。主要是将长序列分成若干个小块,然后对每个块中的信息进行压缩,以便模型能够更高效地处理和记忆这些信息。
在每个Transformer层中,块内压缩通过自注意力机制将当前块的信息压缩成一个固定长度的表示用于反馈记忆的激活。然后再与之前的FAM状态结合,通过一个前馈网络进行更新生成全新的FAM状态。
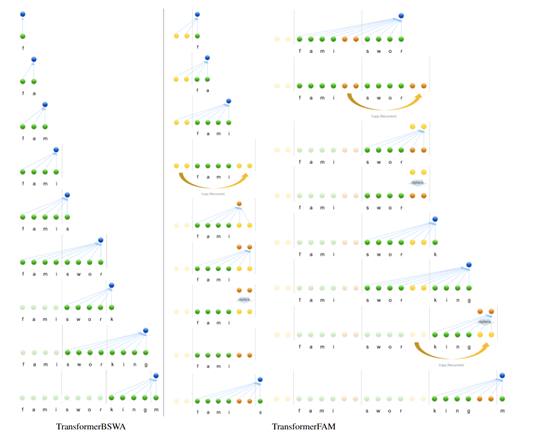
更新后的FAM状态会被传递到下一个块,作为那里的额外上下文信息,从而实现跨块的数据信息传递。
随着模型逐块处理整个序列,新的记忆状态会包含越来越多跨块的信息,从而形成一个全局的上下文理解,但对内存、算力的需求几乎没有额外增加,同时又获得了“记忆存储”的泛化能力。
本文素材来源TransformerFAM论文,如有侵权请联系删除
END
