











ChatGPT、Gemini等文本理解、生成方面现出了前所未有的能力,极大地推动了生成式AI的技术创新。但这些模型在实际应用中有时会生成听起来合理,但实际上并不准确的“幻觉”内容,就是一本正经的胡说八道。
为了解决这一难题,谷歌研究院在官网发布了创新框架AGREE,可增强大模型生成内容和引用的准确性。
研究人员在Llama-2-13b等知名大模型进行了实验,结果显示,与现有方法相比,AGREE在提升内容回答准确性和引用性方面非常出色。
论文地址:https://arxiv.org/abs/2311.09533

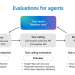
AGREE的核心技术是通过检索文档中的相关段落来增强大模型生成回答的事实基础,并提供相应的引用。这种方法不仅可以提高回答的准确性,还可以为用户提供验证信息真实性的途径,主要由训练阶段微调和测试时自适应两大块组成。
训练阶段微调
训练阶段微调是AGREE提升大模型自我归因能力的关键模块,在生成每一个回答时都能够提供支持其声明的可靠来源。
首先使用基础的大模型生成一系列回答,作为微调流程的起点。然后,使用了自然语言推理模型(NLI),来评估一个给定的段落是否支持一个特定的声明。在AGREE框架中,NLI模型被用来从未标记的查询中自动构建训练数据集。

构建训练数据的过程包括将基础大模型生成的回答与检索到的文档进行匹配,NLI模型会为每个声明找到最相关的支持性段落,并将其作为引用附加到声明上;如果声明没有找到支持的段落,则被标记为未支持。

在微调阶段,AGREE框架采用了LORA的轻量级微调技术,通过在大模型的权重矩阵上添加低秩更新,来实现高效且针对性的调整,有助于减少计算资源的消耗,同时保持模型的泛化能力。
测试时自适应
测试时自适应是一种动态、迭代的推理增强方法,可帮助大模型在面对新的内容查询时,能够主动地从大型语料库中检索相关信息,并对之前生成的回答进行补充和修正。这种方法与传统的静态回答生成方式不同,它强调的是在测试时不断优化和调整回答,以确保生成的内容尽可能准确和全面。

测试时自适应的工作流程开始于接收到一个新的查询,经过微调的大模型会首先根据其训练阶段学到的知识生成一个初步的回答,然后进入一个自动迭代的过程,大模型会自我评估生成的回答,并识别出其中尚未归因或需要进一步支持的声明。
一旦识别出需要额外信息的声明,测试时自适应就会启动检索过程。这一过程涉及到在预先构建的语料库中搜索与未归因声明相关的段落。
这些段落被选出来后,大模型会尝试将它们与先前的回答结合起来,生成一个更加完善、准确的内容。同时会不断迭代循环,直至达到预定的推理效果或模型认为回答已足够完美为止。
本文素材来源AGREE论文,如有侵权请联系删除


