





一个朴素的 RAG 系统流程是这样的:先由用户提出问题,然后系统基于用户提问进行召回,对召回结果进行重排序,最后拼接提示词后送给 LLM 生成答案。

一部分简单场景下,朴素的 RAG 已经可以满足用户意图明确的场景的要求,因为答案已经包含在检索出来的结果中,只要交给 LLM 即可。然而在更多的情况下用户意图并不明确,无法直接通过检索找到答案,例如一些针对多文档的总结类提问需要进行多步推理 (Reasoning) 等等。这类场景就需要引入 Agentic RAG ,也就是在问答的过程中引入任务编排机制。
Agentic RAG,顾名思义,是基于 Agent 的 RAG。Agent 与 RAG 关系紧密,两者互为基石。Agentic RAG 和简单 RAG 的最大区别在于Agentic RAG 引入了 Agent 的动态编排机制,因此可以根据用户提问的不同意图,引入反馈和查询改写机制,并进行“多跳”式的知识推理,从而实现对复杂提问的回答。

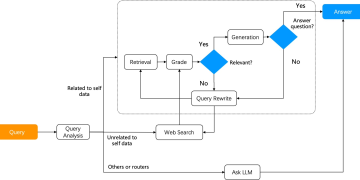
下面,我们先通过两个高级 RAG 来看看 Agentic RAG 的工作原理。首先是 Self-RAG (参考文献[1]),它的工作流程如下:

Self-RAG 是一种引入了反思机制的 RAG。从知识库中检索出结果后,它会评估结果是否与用户提问相关。如果不相关,就要改写查询,然后重复 RAG 流程直到相关度评分达到要求。实现 Self-RAG 需要实现以下两大组件:
- 一套基于 Graph 的任务编排系统。
- 在 Graph 内执行的必要算子:比如在 Self-RAG 中,评分算子就至关重要。在原始论文中, 是需要自己训练一个打分模型来针对检索结果评分;在实际实现中也可以采用 LLM 进行评分,这样可以简化系统开发并且减少对各类环节依赖。
Self-RAG 是相对初级的 Agentic RAG,RAGFlow 中也已提供了相关实现。实践证明,Self-RAG 对于较复杂的多跳问答和多步推理可以明显提升性能。
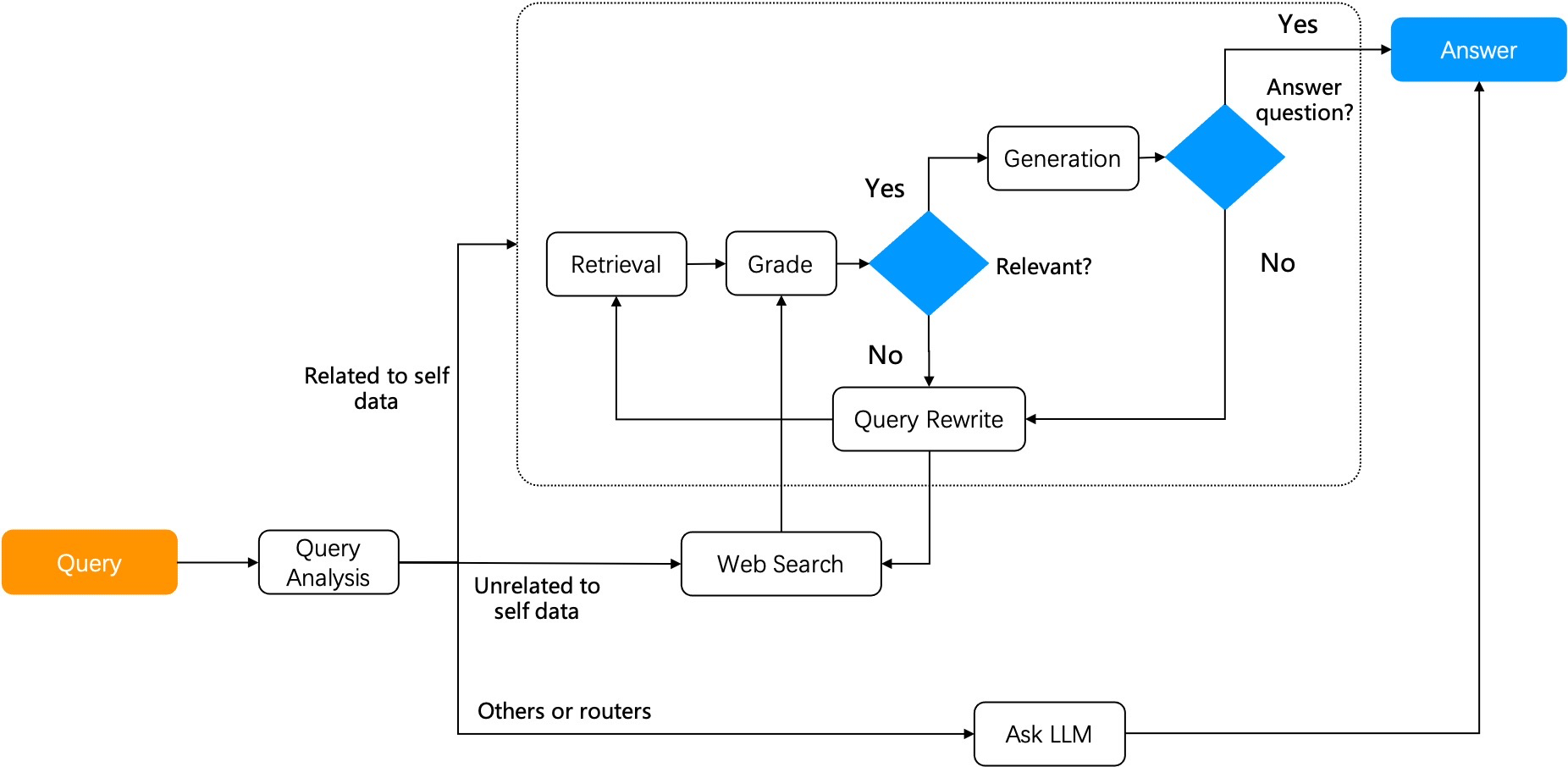
再来看看另一种 Agentic RAG — Adaptive RAG (参考文献[2])。它可以根据用户提问的不同意图采用对应的策略:
- 开放域问答:直接通过 LLM 产生答案而无需依赖 RAG 检索。
- 多跳问答:首先将多跳查询分解为更简单的单跳查询,重复访问 LLM 和 RAG 检索器来解决这些子查询,并合并它们的答案以形成完整答案。
- 自适应检索:适用于需要多步逻辑推理的复杂问题。复杂的问答往往需要从多个数据源综合信息并进行多步推理。自适应检索通过迭代地访问 RAG 检索器和 LLM,逐步构建起解决问题所需的信息链。
如下图所示,Adaptive-RAG 的工作流程与 Self-RAG 类似,只是在前面增加了一个查询分类器,就提供了更多种对话的策略选择。

从以上两种 Agentic RAG 例子可以看出,这类高级 RAG 系统都需要基于任务编排系统上提供以下功能:
- 复用已有的 Pipeline 或者子图。
- 与包含 Web Search 在内的外部工具协同工作。
- 可以规划查询任务,例如查询意图分类,查询反馈等等。
任务编排系统类似的实现主要有Langchain的 ️LangGraph 和 llamaIndex;Agent 的开发框架包括 AgentKit、Databricks最新发布的 Mosaic AI Agent Framework 等等。任务编排系统需要基于图(Graph)来实现,图中的节点和边定义了应用的流程和逻辑。节点可以是任何可调用的算子,也可以是其他可运行组件(比如链接起来的多个算子或者 Agents),每个节点执行特定的任务。边定义了节点间的连接和数据流。图需要具备节点的状态管理功能,从而根据节点的跳转而不断更新状态。需要注意的是,这种基于图的任务编排框架并不是一个 DAG (Directed Acyclic Graph), 而是一个需要引入循环的编排系统。环是提供反思机制的基础,对于 Agentic RAG 的编排至关重要。没有反思机制的 Agent 只能提供类似工作流这样的任务编排而无法实现更高级的多跳和多步推理机制,没法真正像人类那样去思考性地解决问题。在吴恩达给出的四种 Agent 设计模式(参考文献[3])中:反思被放在头一个,其他三个都是工作流相关,分别是工具、规划,和多 Agent 协同。反思被单列出来是因为思考和推理都必须基于它来进行,而 Agentic RAG 正是反思机制在 RAG 的体现。
Agentic RAG 代表了信息处理方式的变革,为 Agent 本身引入了更多的智能。结合了工作流的 Agentic RAG 也有更广阔的应用场景。比如:在文档摘要中,Agentic RAG 会首先确定用户的意图是要求摘要还是要求对比细节。如果是前者,就通过 Agent 先获取每块内容的摘要再获取整体的摘要;如果是后者,就需要进一步路由,通过检索提取相应数据点,再把相关数据传递给 LLM。在客户服务支持中,Agentic RAG 可以理解客户更加复杂的提问,从而可以提供更加个性化的准确回复。在文献助手中,Agentic RAG 可以综合更多的文献、数据和研究结果,让使用者具备更全面的理解;在法律和医疗助手中,Agentic RAG 可以帮助理解和解释复杂的领域知识,提供更准确地见解;在内容生成应用中,Agentic RAG 可以帮助生成更高质量的、上下文相关的企业级长文档。
RAGFlow 将从 v0.8.0 开始原生支持基于图的任务编排系统,并支持以无代码的方式进行编辑;另一方面, RAGFlow 也在不断完善各类查询规划算子以简化 Agentic RAG 以及基于 Agentic RAG 的各类 Agent 应用的开发过程,真正从端到端解决企业级 RAG 应用的各类痛点。RAGFlow 一直在快速演进,欢迎关注、star,并积极参与到我们的项目中来!
项目地址:https://github.com/infiniflow/ragflow
参考文献:
- Self-RAG: Learning to retrieve, generate, and critique through self-reflection, arXiv preprint arXiv:2310.11511
- Adaptive-RAG: Learning to adapt retrieval-augmented large language models through question complexity, arXiv preprint arXiv:2403.14403
- https://www.deeplearning.ai/the-batch/issue-242/
