






苹果的研究人员开源了最新通用多模态视觉模型AIMv2,有300M、600M、1.2B和2.7B四种参数,整体能耗很低,可以适用于手机、PC等不同类型的设备。
与传统视觉模型不同的是,AIMV2 使用了一种创新的多模态自回归预训练方法,将视觉与文本信息深度融合,为视觉模型领域带来了新的技术突破。
简单来说,就是AIMV2 不再局限于仅处理视觉信息的传统模式,而是将图像和文本整合为统一的序列进行预训练。在这个过程中,图像被划分为一系列不重叠的Patches,形成图像token序列。
文本则被分解为子词令牌序列,然后将两者拼接在一起。这种独特的拼接方式使得文本令牌能够关注图像令牌,实现了视觉与文本信息的交互融合。


例如,在处理一张风景图片和相关描述文字时,AIMV2可以通过这种融合方式更好地理解图片中的元素与文字描述之间的对应关系,包括图片中的山脉、河流等元素与文字中提及的自然景观特征的关联。

开源地址:https://github.com/apple/ml-aim
Huggingface地址:https://huggingface.co/collections/apple/aimv2-6720fe1558d94c7805f7688c
AIMV2技术架构
在以往的研究中,专家模型被设计来最大化特定任务的性能,而通用模型则能够被部署在多个预定义的下游任务中,仅需最小的调整。
但随着大语言模型GPT系列的成功,预训练模型已成为自然语言处理领域的主流范式。这些模型通过生成预训练或对比学习等方法,学习了大量的语言表示。在机视觉领域,尽管生成预训练在语言模型中占据主导地位,但在视觉模型中的表现却落后于判别方法。
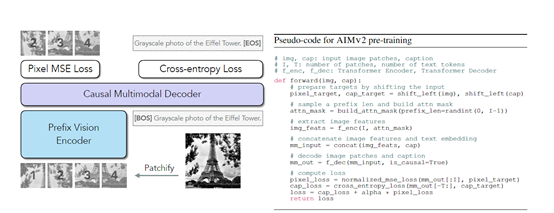
AIMV2的核心技术在于其多模态自回归预训练框架。这一框架将图像和文本整合到一个统一的序列中,使得模型能够自回归地预测序列中的下一个标记,无论它属于哪种模态。

在预训练阶段,AIMV2使用一个因果多模态解码器,首先回归图像块,然后以自回归的方式解码文本标记。这种简单的方法有几个巨大技术优势:AIMV2易于实现和训练,不需要非常大的批量大小或特殊的跨批次通信方法;
AIMV2的架构和预训练目标与LLM驱动的多模态应用非常吻合,可以实现无缝集成;AIMV2从每个图像块和文本标记中提取训练信号,提供了比判别目标更密集的监督。
训练流程与测试数据
在预训练目标方面,AIMV2定义了图像和文本领域的单独损失函数。文本领域的损失函数是标准的交叉熵损失,用于衡量每一步中真实标记的负对数似然。图像领域的损失函数是像素级的回归损失,模型预测的图像块与真实图像块进行比较。
整体目标是最小化文本损失和图像损失的加权和。这种损失函数的设计旨在平衡模型在图像和文本两个领域的性能,同时鼓励模型学习到能够准确预测两个模态的表示。
AIMV2的预训练过程涉及到大量的图像和文本配对数据集。这些数据集不仅包括公开的DFN-2B和COYO数据集,还包括苹果公司的专有数据集HQITP。这些数据集的结合为AIMV2提供了丰富的预训练数据,使其能够在多种下游任务中表现出色。

预训练过程中,图像被划分为非重叠的图像块,文本序列被分解为子词,然后这些序列被连接起来,允许文本标记关注图像标记。这种处理方式使得AIMV2能够处理不同分辨率和长宽比的图像,提高了模型的灵活性和适应性。
在性能测试方面,AIMV2在多个领域展现出了卓越的性能。在图像识别方面,AIMV2在ImageNet-1k数据集上达到了89.5%的准确率,这还是在冻结模型主干的情况下完成的。
此外,与其他视觉语言预训练基线模型相比,AIMV2 同样展现出了高度竞争的性能。例如,在ViT-Large容量下,AIMV2 在大多数基准测试中优于OAI CLIP,并在 IN-1k、iNaturalist、DTD和 Infographic 等关键基准测试中超越了DFN-CLIP 和 SigLIP。

值得注意的是,AIMV2 在训练数据量仅为 DFN-CLIP 和 SigLIP 的四分之一(12B vs. 40B)的情况下,仍能取得如此优异的成绩,且训练过程更加简便、易于扩展。
此外,AIMV2在开放词汇对象检测和指代表达理解等任务上也表现出色,显示出其在多模态任务中的广泛适用性。
本文素材来源苹果,如有侵权请联系删除
