








今天凌晨,知名大模型训练、开发平台Predibase发布了,首个端到端强化微调平台(RFT)。
与传统的监督式微调相比,RFT不依赖大量的标注数据,而是通过奖励和自定义函数来完成持续的强化学习,同时支持无服务器和端到端训练方法,从数据管理、训练模型到应用部署可以在同一个平台全部完成。
也就是说,你只需要一个浏览器,设定微调目标、上传数据、就能完成以前非常复杂的大模型微调流程。

在线体验地址:https://predibase.com/reinforcement-fine-tuning-playground
为了展示RFT强大功能,Predibase根据阿里开源的Qwen2.5-Coder-32B-instruct,微调了一个专门用于将PyTorch代码翻译为Triton的模型。
这是一个大多数LLM都难以完成的任务,需要对两个框架都有深入的理解,并且需要复杂的推理能力来考虑计算效率,并且Qwen2.5-Coder-32B-instruct在微调之前准确率比较低。
通过RFT,Predibase在训练过程结合了冷启动监督式微调、强化学习和课程学习,并且只使用了十几个标记数据点。


在Kernelbench数据集上进行的基准测试显示,Qwen2.5-Coder-32B-instruct经过强化后,其正确率比DeepSeek-R1和OpenAI的o1高出3倍,比Claude 3.7 Sonnet高出4倍以上,而模型的体量却比这三个小很多。
目前,Predibase已经开源了微调后的Qwen2.5-Coder-32B-instruct模型。

开源地址:https://huggingface.co/predibase/Predibase-T2T-32B-RFT
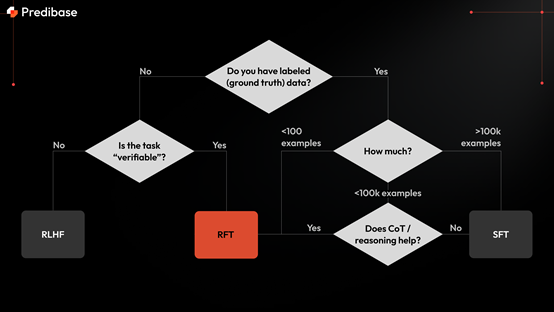
技术优势方面,RFT不依赖大量标注数据,而传统方法需要海量标注数据来指导模型学习,这些数据通常需要人工标注,成本高昂且耗时。RFT则通过奖励函数来引导模型学习,无需大量标注数据,奖励函数可根据任务的特定需求评估模型输出,来引导模型的优化目标。
RFT的适应性与灵活性更强。传统方法依赖于标注数据的质量和数量,若标注数据有限或不准确,模型性能会受限。而RFT允许用户根据具体任务需求自定义奖励函数,灵活定义模型优化目标。
例如在代码生成任务中,可定义奖励函数验证代码正确性;在问答任务中,可定义奖励函数评估答案相关性和准确性。

RFT具备持续改进能力。传统方法通常是一次性过程,模型训练完成后难以继续改进。RFT则支持持续改进,随着奖励函数优化和更多反馈数据积累,模型能不断学习和改进,适应任务需求变化。
在训练与推理效率方面,传统方法通常需在本地环境中进行,对硬件资源要求高,且需手动管理训练和部署过程。
而Predibase提供的RFT平台是完全托管的无服务器平台,用户无需管理底层服务器或基础设施,平台自动处理训练、部署和推理全过程,大大降低了开发和运维复杂性。此外,RFT利用多LoRA框架和流式微批处理技术,实现了高效的训练和推理。

RFT还支持复杂任务的课程学习。传统方法在处理复杂任务时,通常需大量标注数据覆盖各种情况,否则模型难以学习到有效策略。RFT则支持课程学习,即从简单到复杂逐步训练模型,使其能处理更复杂任务,这在需要深度推理的任务中特别有效。
在模型部署方面,传统方法部署模型通常需额外工具和配置,且难以保证高性能。Predibase的推理引擎原生支持RFT训练的模型,并提供高性能的无服务器部署解决方案,用户可将训练好的模型快速部署到生产环境中,并获得行业级服务水平支持。
RFT还具备更好的泛化能力。传统方法可能会导致模型过度拟合标注数据,从而在未见过的数据上表现不佳。RFT通过奖励函数引导模型学习,使模型能更好地泛化到未见过的数据上,提升其在实际应用中的鲁棒性。

Predibase表示,DeepSeek在开源R1之后,在全球AI领域产生了巨大影响,让很多人意识到强化学习微调对训练大模型的重要性。受此启发,他们开发了这个端到端无服务器强化微调平台。
本文素材来源Predibase,如有侵权请联系删除
