








今年2月初,谷歌发布的Gemini 2.0 Pro支持200万上下文,震惊了整个大模型领域。
仅过了2个月,Meta最新开源的Llama 4 Scout就将上下文扩展至1000万,整整提升了5倍开启千万级时代。对于这么大的窗口大家可能没什么概念,普通版本的《战争与和平》大概有1300页100万字左右,Llama 4 Scout可以一次性解读这本书。
如果你开发完一个项目想让大模型帮你检查一下是否有BUG、可优化的地方,只要代码少于1000万token,Llama 4 Scout都能帮你解决。惊不惊喜,整个代码库都成提示词了~




开源地址:https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164
Llama 4 Scout简单介绍
Llama 4 Scout是一个专家混合架构模型,一共有1090亿参数。其中,有170亿活跃参数和16个专家路由,能在单个H100 GPU上使用,具备原生多模态的能力,可以处理文本和图像,支持最多8张图像的输入。
架构创新方面,Llama 4 Scout使用了无位置交叉嵌入的交错注意层NoPE。传统的Transformer架构通过位置编码将每个单词的位置信息嵌入到模型中,从而使模型能够区分不同位置的单词。
但这种显式的位置编码方法在长度泛化方面存在局限性。例如,当模型在训练时接触到的序列长度较短,在测试时需要处理更长的序列时,显式位置编码可能无法有效地泛化到这些未见过的长度。而NoPE可以很好解决这个难题。

NoPE的设计非常简洁,就是直接移除了Transformer模型中的位置编码部分。这意味着使用NoPE架构的模型中,输入序列的单词不会被附加任何显式的位置信息。模型仅依赖于其自注意力机制和前馈网络来处理序列数据。
在NoPE模型的第一层中,通过特定的权重设置,模型可以恢复输入序列的绝对位置信息。模型可以通过自注意力机制和前馈网络将绝对位置信息写入隐藏状态。这一过程依赖于模型的因果注意力掩码和softmax函数,使得模型能够从输入序列中恢复绝对位置信息。
在后续层中,NoPE可以实现相对位置编码。通过特定的权重设置,模型可以使得注意力机制依赖于单词之间的相对距离,而不是绝对位置。NoPE可以捕捉到单词之间的相对位置信息,从而实现相对位置编码。

根据测试数据显示,NoPE在长度泛化方面表现出色,超过了所有显式位置编码方法。在多种推理和数学任务中,NoPE能够成功地从较短的训练序列泛化到更长的测试序列。
例如,在加法任务中,NoPE在长度为40的序列上的准确率达到了0.69,而其他位置编码方法的准确率均低于0.55。这表明NoPE能够更好地捕捉序列中的数学规律,并将其应用于更长的序列。
NoPE的计算效率也更高。由于不需要计算额外的注意力机制项,因此在训练和推理过程中都能节省时间和计算资源,尤其是在需要处理长序列的任务中。
所以,Llama 4 Scout拥有1000万上下文却能在单个H100使用,NoPE发挥了非常大的作用。
训练数据方面,Llama 4 Scout使用了30万亿token数据,包括文本、图像、视频,比之前开源的Llama 3高两倍。
此外,Llama 4 Scout在预训练阶段还特别注重多语言能力的培养,在200种语言上进行了训练,其中包括超过100种拥有超过10亿标记的语言,使得Llama 4 Scout在处理跨语言任务时具备了强大的语言理解和生成能力。
媲美DeepSeek V3的新模型
除了Llama 4 Scout,Meta还开源了一个模型Llama 4 Maverick,同样是专家混合模型,一共有4000亿参数。其中,170亿参数处于活跃状态和128个专家路由。同样可以在单个H100运行,不过只有100万上下文。
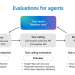
Maverick使用的训练方法和数据与Scout差不多。根据公布的测试数据显示,Maverick在MMLU/Pro、GPQA、DocVQA、MathVista超过了谷歌的Gemini 2.0和OpenAI的GPT-4o,可以媲美DeepSeek最新开源的V3模型。

训练创新方面,Meta在训练Maverick时,用了一种新办法来优化训练流程包括三个步骤:先进行轻量级监督微调(SFT),接着开展在线强化学习(RL),最后做轻量级直接偏好优化(DPO)。
但在这个过程中,有一个重要问题:SFT和DPO这两个步骤,可能会对模型限制得太厉害。这就会让模型在在线RL这个阶段没办法充分地去探索各种可能性,结果就是模型在做推理、编码以及数学相关任务的时候,算得没那么准表现不佳。
为了解决这个难题,Meta剔除了超过50%被标记为“简单”的数据,并在剩余更具挑战性的数据集上进行轻量级SFT。在随后的多模态在线RL阶段,通过精心挑选更具挑战性的提示,实现了性能的显著提升。
此外,Meta实施了连续在线RL策略,即交替进行模型训练,然后利用训练好的模型持续筛选并仅保留中等至较难难度的提示。

事实证明,这种策略在计算成本和准确性的权衡方面非常有效。接着进行了轻量级DPO,以处理与模型响应质量相关的极端情况,有效地在模型的智能和对话能力之间实现了良好的平衡
正训练2万亿参数教师模型——Llama 4 Behemoth
Meta表示,Scout和Maverick只是开源的首批Llama 4系列模型。正在训练一个总参数2万亿,活跃参数2880亿活跃参数和16个专家路由的教师模型——Llama 4 Behemoth。
Llama 4 Behemoth主要用于蒸馏、微调小模型,Llama 4 Maverick便是通过它完成的。为了实现性能的最大化,Meta对SFT数据进行大幅删减,要剪掉95%的数据,而较小的模型仅需剪掉50%,以此来实现对质量和效率的必要关注。
由于两万亿参数模型前所未有的规模,为其扩展强化学习(RL)还需要对底层的强化学习基础设施进行改造。
Meta开发了一个完全异步的在线强化学习训练框架,增强了灵活性。现有的分布式训练框架为了将所有模型堆叠到内存中,牺牲了计算内存。新基础设施能够将不同模型灵活分配到单独的GPU上,根据计算速度在多个模型之间平衡资源,训练效率比上一代提升了大约10倍。

根据实验数据显示,Llama 4 Behemoth在MMLU Pro、GPQA、MATH-500等测试的数据比GPT-4.5、Claude Sonnet 3.7、Gemini 2.0 Pro更好。
本文素材来源Meta,如有侵权请联系删除
