


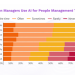






OpenAI的GPT系列、DeepSeek R1以及Qwen等模型,都通过强化学习(RL)技术显著提升了推理能力。强化学习通过奖励机制引导模型探索最优解,但这一过程面临着诸多挑战,例如,训练不稳定、策略漂移等问题。
为了解决这些难题,快手科技的Klear团队提出了创新框架RLEP,通过收集已验证的优质轨迹并在后续训练中重放,显著提升了大模型训练效率和最终性能。

RLEP框架的核心思想是将经验回放技术引入到大型语言模型的强化学习训练中。这一思想的灵感来源于人类学习的过程:当我们面临复杂的任务时,往往会从过去的成功经验中汲取智慧,避免重复犯错,从而更高效地达成目标。

在强化学习中,模型通过不断地探索和试错来学习最优策略,但这一过程往往伴随着大量的无效探索和策略的不稳定。RLEP通过记录模型在训练过程中成功探索到的高质量推理路径,并在后续的训练中重新利用这些路径,使得模型能够快速恢复之前的最佳性能,并在此基础上进一步提升。

RLEP框架分为经验收集和基于回放的训练两大阶段。经验收集阶段是整个流程的基础。这一阶段的目标是从模型的初始策略出发,探索并记录那些能够成功解决问题的推理路径。具体来说,对于每一个输入问题,模型会根据当前的策略生成一组候选答案,这些答案通常是以推理轨迹的形式呈现,包含了从问题到答案的完整推理过程。
然后,通过一个奖励模型对这些候选答案进行验证,判断哪些答案是正确的。这些验证通过的轨迹,也就是成功轨迹,会被保留下来,并存储到经验池中。
经验池的构建是RLEP框架的关键之一。不仅保存了模型在早期训练中发现的有效推理路径,还为后续的回放训练提供了丰富的素材。在经验收集阶段,模型会不断地探索新的路径,并将成功路径添加到经验池中。这个过程就像是模型在“标记”那些能够成功解决问题的路径,为后续的训练提供了一个可靠的“地图”。通过这种方式,经验池逐渐积累了大量高质量的推理路径,为后续的回放训练奠定了坚实的基础。

在经验收集阶段构建了经验池之后,RLEP框架进入基于回放的训练阶段。这一阶段的目标是通过回放经验池中的成功轨迹,快速恢复模型之前的最佳性能,并在此基础上进一步提升模型的性能。
在每次训练更新时,模型会生成一组新的推理轨迹,这些轨迹是基于当前策略生成的,包含了模型对当前问题的理解和推理。同时,模型还会从经验池中随机抽取一部分成功轨迹,并将这些轨迹与新生成的轨迹混合在一起。然后,模型根据这些混合轨迹计算优势函数并更新策略。
回放训练阶段的关键在于如何平衡巩固知识和探索新路径之间的关系。一方面,通过回放经验池中的成功轨迹,模型能够快速恢复之前学到的有效知识,避免在无效的路径上浪费时间。这就好比登山者在攀登过程中,沿着之前标记的路径前进,能够更快地达到已知的高点。
另一方面,模型仍然会生成新的推理轨迹,这使得模型有机会探索新的路径,发现更优的解决方案。这种混合的方式既保证了模型能够充分利用之前的经验,又不会陷入局部最优,从而实现更快的收敛和更高的最终性能。

此外,为了进一步提高GRPO的稳定性和效率,RLEP使用了两种优化策略。首先是token-mean策略,它通过逐token计算对数概率比,而不是在整个序列上进行平均,从而避免了长序列在整体平均时被低估的问题。这种策略能够更好地保留长序列的学习信号,使得模型在处理长推理路径时更加有效。
clip-higher策略通过不对称地裁剪正优势轨迹的上界,防止了探索空间的坍塌。这种策略在保持模型探索能力的同时,也避免了模型过度依赖某些高奖励的路径,从而平衡了利用与探索的关系。
