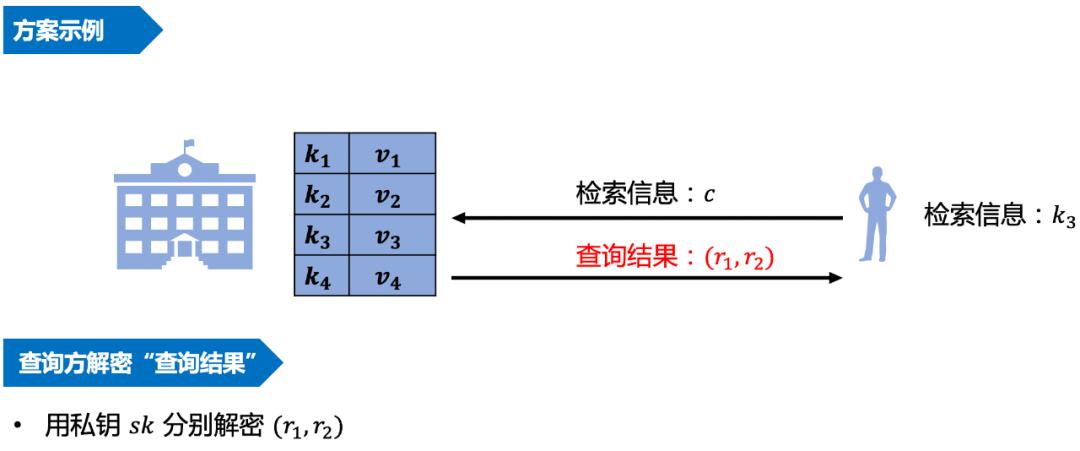
隐匿信息查询 (Private Information Retrieval, PIR) 是一种安全的信息查询协议。是安全多方计算中非常实用的一门技术与应用,可以用来保护用户的查询隐私,进而也可以保护用户的查询结果。其目标是保证用户向数据源方提交查询请求时,在查询信息不被感知与泄漏的前提下完成查询。即对于数据源方来说,「只知道有查询到来,但是不知道真正的查询条件、也就不知道对方差了什么」。
例如:现在有个股神,很多人都关注他炒股的一举一动,把他关注的股票作为购买的参考,但是股神不想泄露这些信息以免影响股票价格,这个时候,股神就可以使用「隐匿信息查询技术」来查询股票信息,保证他查询数据时的隐私性。
PIR有多种实现的方式,每种方式各有安全性/性能的差异,有多种基于密码学的方案,包括基于不经意传输(OT)的PIR、基于同态加密的PIR等。
PIR从服务端数量的角度,分为多server PIR、单server PIR。本文我们介绍的是单server PIR。
基于OT的PIR
• 原理:客户端和服务端执行n选1OT,客户端获取服务端n个密钥中的的1个密钥。服务端对n条数据进行加密,客户端可以解密其中的一条数据。
• 安全性:依赖于公钥密码算法和对称密码算法安全性。
• 通信性能:通信复杂度为O(n)
基于同态加密算法的PIR
• 原理:基于公钥加密算法的同态性质,通过客户端的查询向量与服务端所有数据构造的向量的内积运算,完成PIR。
• 安全性:依赖于同态加密算法的安全性。
• 通信性能:在最新的Onion PIR和Spiral PIR方案中,通信复杂度只有O(1)
基于hash函数的PIR(MD5截取)
• 原理:客户端计算查询数据的数据哈希值,并将hash值的后若干比特发送给服务端。服务端计算所有数据的哈希值,将所有哈希值的后若干比特于客户端发送的数据匹配,并将所有匹配上的结果返回给客户端。
• 安全性:查询的不可区分度取决于用于匹配的哈希值长度。该方案会一定程度的泄露查询信息,服务端会知道客户端的查询属于属于某原始数据中的一个集合。若截取的哈希值长度较大,则集合内数据较小,PIR方案的不可区分度很低,若截取的哈希值长度较短,则集合内数据较多。
• 通信性能:通信量同样与用于匹配的哈希值长度相关。服务端会知道客户端的查询属于属于某原始数据中的一个集合,服务端会将该集合内的所有数据返还给客户端。若截取的哈希值长度较大,则集合内数据较小,若截取的哈希值长度较短,则集合内数据较多。
三种方案安全性能:
|
方案路线
|
安全性
|
性能
|
|
基于OT的PIR
|
中
|
中
|
|
基于全同态加密的PIR
|
高
|
中
|
|
基于hash函数的PIR(MD5截取)
|
低
|
高
|
Ps:基于全同态加密的PIR可以保证客户端数据安全性,MD5截取严格来说并不属于PIR
如上面所述,PIR协议允许客户端在服务端无法知道查询内容的前提下,得到查询的数据。双方通过运行密码学协议,交换加密后的数据,得到PIR的查询结果。这种特性很像手套箱,即可以通过一个有两个手套的箱子,隔着手套操作箱子里的物品,但手无法直接碰到物品。

另外这里还有另一个保证,即客户端不能获得非查询内容的信息。
这样PIR协议有了比较完整的安全特性。可以简单的的认为对于客户端和服务端,双方的数据都是安全的。在实际业务中有各种各样的应用,例如:
• 向银行/征信机构查询信用评分
• 反诈/公安/风险评估黑名单查询
• 用户特征查询
DataTrust目前支持基于全同态加密的Keyword-PIR方案,支持10亿级的用户数据查询,支持多key列和多value列查询。DataTrust的Keyword-PIR方案是基于DataTrust基于全同态加密的非平衡PSI协议([CMG21] @ CCS 2021)的扩展,能在单机小时级实现10亿级数据量的PIR查询。本文主要介绍DataTrust PIR的工程架构。
与DataTrust的非平衡PSI工程架构类似,我们分为算子和协议编译、计算框架、其他技术问题进行介绍。
• 基础算子:数据加载(LOAD)、通信(SEND/RECEIVE)、结果输出写表(SAVE)算子,可以支持多种数据源和通信方式
• 分桶:用户输入的数据可以是任意的,并且在产品的任务配置界面上,用户可以选择多个字段进行PIR计算。与非平衡PSI算法类似,PIR也需要双方对同一个桶中的内容进行计算,才能保证得到准确的结果,因此需要双方使用共同的分桶规则,对每侧的数据各自进行分桶计算。在这步中,分桶算子根据计算逻辑和分桶配置,输出M个桶的文件
• PIR:我们将PIR算子,根据PIR协议的角色和计算步骤,分为多个step。每个step负责不同的计算逻辑。对于客户端和服务端,都需要依赖前面计算步骤的计算结果,进行下一步计算。因此对于PIR算子,需要理解算法的计算流程,设计不同的计算逻辑
• PIR预计算(PirPreCache):对于同一份数据,目前的Keyword-PIR算法可以提前对服务端的数据进行预计算。这样当客户端对同一份服务端数据进行多次不同的查询时,可以复用预计算的结果,优化PIR的性能。PirPreCache只需要输入服务端的数据,不需要客户端提供数据。
• PIR:使用PirPreCache任务的结果,运行PIR协议,得到查询的key和value。
在产品使用上,用户先配置PirPreCache任务并完成运行。然后配置PIR任务,指定依赖的PirPreCache任务,进行PIR查询。支持多个PIR查询任务依赖同一个PirPreCache任务的结果。

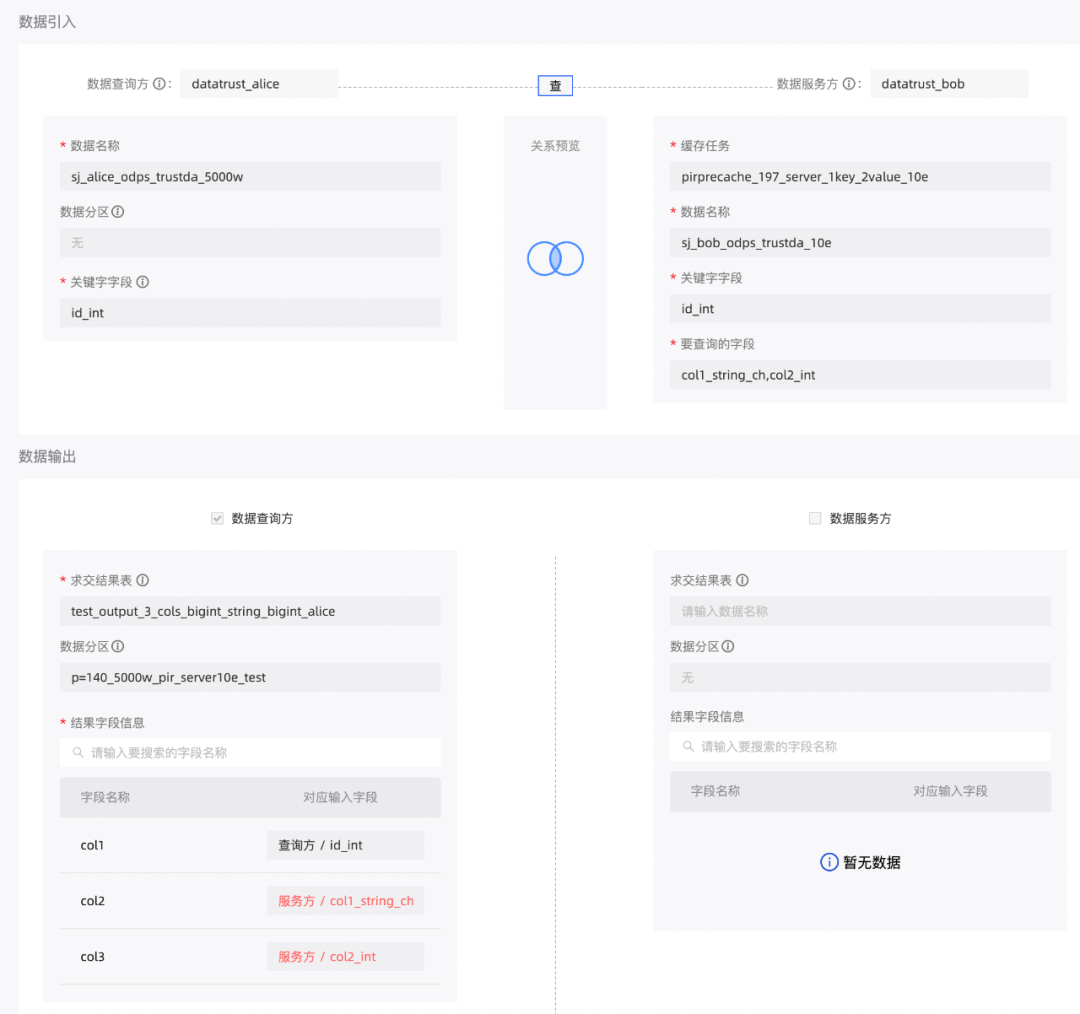
在PIR实现中,我们使用了多个基于C/C++的密码算法库。我们在任务运行时加载动态链接库,并通过JNI调用进行计算,将算子逻辑代码和so库打包在算子镜像中,可以较好解决运行环境相关的问题。
框架整体延用了DataTrust中非平衡PSI的框架。我们从原始的协议POC代码入手设计工程框架,解决了计算并行化、计算调度控制、步骤拆分、通信传输优化、计算结果序列化/反序列化、任意数据单机离线验证调试等工程问题,实现了支持10亿级数据量的PirPreCache和PIR计算。总体思路仍然是将大数据量进行分桶处理,以单桶-单桶的计算逻辑为基准,进行多pod、多分桶的调度和控制,并面向批量数据计算和传输的特性进行性能优化。
• PIR任务的框架支持客户端启动多pod以提升性能
• PIR任务的最后一个step(即全同态解密恢复PIR结果)支持每个pod内启动多个子线程,并行计算多个分桶。每个分桶的计算过程也支持多线程,进一步提升性能
• PIR任务使用的分桶数由PirPreCache中服务端的数据量自动计算。在PirPreCache的预计算结果中保存一部分PIR任务需要使用的配置信息。PIR任务读入这些配置后进行初始化
• 支持计算中间结果压缩。对于PirPreCache和PIR计算,DataTrust使用OSS进行批量文件传输通信。在计算过程中会产生较多的小文件。通过压缩后传输再解压缩的方式,减少传输的文件数量
PIR延用了DataTrust中非平衡PSI使用的分桶、单分桶再切片、多进程计算分配、计算资源管理等,并进行了进一步稳定性和性能的优化。
此外,由于部分计算支持C和Java的两种版本实现,在DataTrust的工程框架中,还支持从CSCC通过配置下发的方式,切换使用不同的实现代码,以提升稳定性/性能。这个功能已支撑DataTrust对外交付客户。
在大量学术理论研究的基础上,瓴羊隐私计算(DataTrust)根据 PIR 的实际应用场景进行了一系列深入研究和应用探索,涵盖了离线批量查询以及在线实时查询两大类。基于DataTrust产品的本地计算引擎、ODPS数据源、通信带宽1000Mbps、PIR查询value长度33 bytes的测试环境下,得到如下数据:
隐匿信息查询技术不但保证了查询方信息的安全性,而且平衡了查询性能。瓴羊隐私计算(DataTrust)在前沿理论研究的基础上,结合自身在安全多方计算领域多年的实战经验,对匿踪查询进行了深度优化与改造,推出了基于全同态加密的Keyword-PIR方案,能够在满足安全性的基础上进一步提升性能、降低资源开销及部署门槛,使其满足更多实时应用场景的商业落地。


大佬观点
本篇文章来源于微信公众号: 数字金融网